
Google a pris des mesures pour bloquer les scrapers Web qui récoltent les données de ses pages de résultats de moteur de recherche (SERP), entraînant des pannes mondiales pour plusieurs outils de suivi de classement comme Semrush .
Cette initiative de Google a suscité discussions et inquiétudes parmi les professionnels quant à ses répercussions potentielles sur les stratégies de référencement. En plus de perturber les outils de suivi des données, elle peut également entraîner une augmentation des coûts d’extraction des données.
Le fonctionnement de plusieurs outils SEO est perturbé
Search Engine Journal rapporte qu’un utilisateur a noté que l’outil Scrape Owl ne fonctionnait plus (discussion groupe Facebook privé SEO Signals Lab), tandis que d’autres ont observé que les données de Semrush avaient cessé de se mettre à jour.
Entre-temps, une publication sur LinkedIn mentionnait que si des outils comme Sistrix et MonitorRank étaient toujours opérationnels, d’autres avaient du mal à actualiser leurs données.
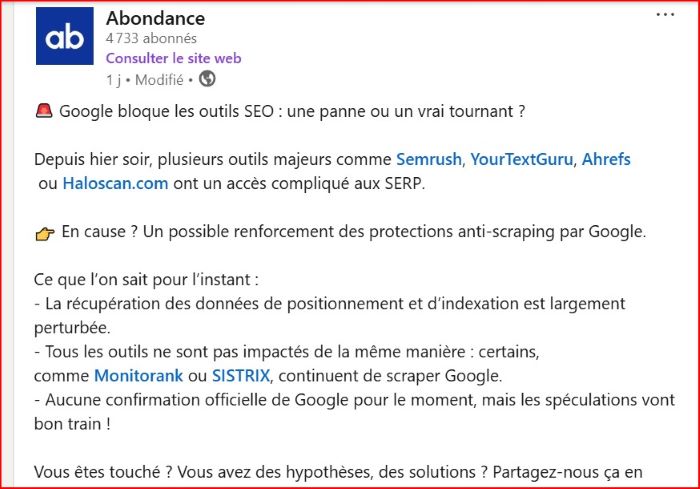
Abondance en parle dans son blog et sur son compte LinkedIn
Cette décision perturbe le suivi des mots clés, la surveillance des classements et d’autres mises à jour de données sur lesquelles ces outils s’appuient, ce qui peut entraîner des informations retardées ou incomplètes.
Si vous dépendez de ces plateformes pour suivre les performances de votre site Web, vous risquez de faire face à des mises à jour plus lentes, à une précision des données réduite et à d’éventuelles augmentations de prix à mesure que ces outils s’adaptent aux restrictions de Google.
L’extraction des résultats de recherche de Google est depuis longtemps interdite par les directives de l’entreprise. Malgré cela, de nombreux outils s’appuient sur ces pratiques pour fournir des données de suivi et de classement des mots clés. Comme le stipulent les directives de Google :
« Le trafic généré par machine (également appelé trafic automatisé) fait référence à la pratique consistant à envoyer des requêtes automatisées à Google. Cela comprend la récupération des résultats à des fins de vérification du classement ou d’autres types d’accès automatisés à la recherche Google effectués sans autorisation expresse.
Le trafic généré par les machines consomme des ressources et interfère avec notre capacité à mieux servir les utilisateurs. De telles activités enfreignent nos règles anti-spam et les conditions d’utilisation de Google.
Désormais, le défi pour Google consiste à bloquer efficacement les scrapers sans impacter les utilisateurs légitimes.
S’adapter aux changements !
En raison de ses effets sur les outils de référencement, certaines entreprises se sont adaptées aux mesures plus strictes de Google, selon le Search Engine Journal.
Dans un cas, un représentant de HaloScan a indiqué que son équipe avait ajusté ses méthodes et repris le scraping avec succès.
De même, MyRankingMetrics semble avoir évité les perturbations, ce qui suggère que les tactiques de blocage actuelles de Google peuvent cibler des comportements de scraping spécifiques ou se concentrer sur les plus grands acteurs du domaine.
Alors que Google intensifie ses efforts pour bloquer le trafic automatisé, certains experts prédisent que l’extraction de données deviendra également plus difficile et plus coûteuse.
Malgré les perturbations généralisées, le géant de la technologie n’a pas encore publié de déclaration officielle concernant la situation.
Bien que l’ampleur réelle des changements reste floue, les spécialistes du marketing ne peuvent que spéculer sur ce qui se passera ensuite.
En attendant, Google ne se concentre pas uniquement sur l’amélioration de sa technologie de recherche. La société a dévoilé sa fonction TV intégrée à l’IA Gemini lors du CES 2025 qui vient de s’achever.
Vous pourriez être intéressé par l’abandon de Google de l’extension Web Vitals et l’intégration de ses fonctionnalités à DevTools.





